How to group time zones

Intro
In the following paragraphs I will discuss how to effectively group similar time zones. First I will introduce a definition of what is meant with “similar” time zones and then present the approach that me and my team came up with in the end.
Recap
In my last article, I presented our approach to rebuild the time zone picker that our customers are using. I started with a short competitor analysis / discovery and from that I derived the final solution that is now live in production:
Grouping equivalent time zones, name them by the largest cities and prefix them by the current time in that time zone.
Below you can see the current result with the labels of each group.

The “LMGTF” approach
Now, given that our designer presented us the above version, we were not sure how to calculate the grouped time zones. 🤔
At first, we thought this would be one of those “let me google that for you” tasks and we indeed found some interesting articles and pages, e.g.:
- https://ux.stackexchange.com/questions/21409/how-to-make-selecting-a-timezone-more-user-friendly
- https://time.is/time_zones
- https://gist.github.com/sandcastle/ad1e527388cad4b1236d68724a78db00
However, we did not find any good resource which suited our case, as we needed a grouping that is future proof (in case a time zone changes their definition) and that we could simply copy into our application.
For example, the last link in the above list actually is a grouping by UTC offsets, however, this does not take not into account that those might change over time, when time zones are updated or when daylight saving time changes their offset.
Off we were back to square one.
Though it felt a little bit like having the NIH syndrome, we had to come up with an own solution to the problem.
Definition of “Similarity”
Before we started, we first had to zoom out and define by which rules we actually want to group time zones. Only then we could come back to the task and create the algorithm for this:
We define two time zones of the same group, if they
- have the same time and date (🙂)
- are on the same continent (🤨)
- have the same support of daylight saving time (🤯)
Rule #1 is pretty obvious: If two time zones result in the same date and time, given a timestamp, they should be in the same group.
Bonus points come with rule #2, as it might make a difference for the user who lives in, e.g., Equatorial Guinea to not be assigned to the same group as Europe/Berlin, even though both belong to UTC+01:00.
Rule #3 came in late to the party, but was actually the toughest rule to apply. You see, in Germany, we have actually two time zones (CET and CEST) which respectively translate to UTC+01:00 during the winter and UTC+02:00 during the summer. So, we cannot easily follow the list on Wikipedia and merge time zones by their UTC listing. We also need to consider their change of daylight saving time — which every country can basically choose on its own if and when to switch to DST.
Given those rules, we then came then back to our algorithm that could be expressed in this rough pseudo-code:
tz1 = pop(all_tz)
current_group = [tz1]
while(is_not_empty(all_tz)) {
tz2 = get_first(all_tz)
if (tz1.currentTime == tz2.currentTime) {
if (tz1.prefix == tz2.prefix) {
if (tz1.dateOfDSChange == tz2.dateOfDSChange) {
current_group.push(pop(all_tz))
continue_with_loop()
}
}
}
}Initially — living in our European bubble with only a handful of time zones — we thought to simply group the different time zones by hand, as there are “only” 388 to look at. However, especially checking for rule #3 became very hard for human beings, simply because there is no easily readable data format for this.
Furthermore, our goal was to come up with a method that we could apply once every year to check if the groups are stable. With the above manual approach, this would be too much time invested.
Coming to the best parts of being a computer scientist: Solving an existing problem with technology! 🤓 🤩
The script
Achieving the above sketched algorithm is actually quite straight forward, as the “hard” part of making the basic data accessible was already done by the great people that built and maintain the momentJS library. 👏 👏 👏
Using this library, we check for similarity (rule #1) by iterating over a given time interval and converting each day in-between this interval with each time zone. This actually gives us the check for rule #3 for free 😍.
Example
Given the interval between 2020-01-01 and 2020-01-04, we can represent this in the following manner:
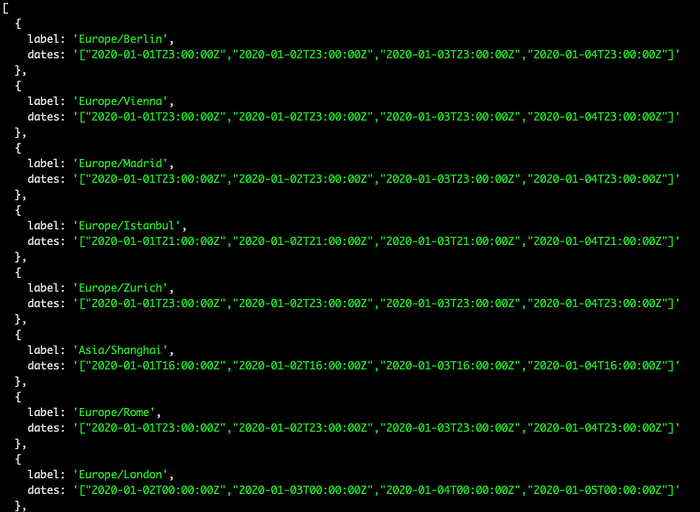
As you can see in the above image, Europe/Berlin and Europe/Vienna have the same array representation and hence match our presented definition.
However, Europe/Berlin and Europe/London for example do not match, as they are in fact in different time zones and hence their representation differs when converted.
More specific
Once we have this representation, the algorithm then only has to compare each with every time zone, resulting in a runtime of O(n^2).
timezones = [....] // put list of timezones here
START_DATE = 2020-01-01
END_DATE = 2025-01-01GROUPS = []foreach (tz in timezones) {
timezones.remove(tz)
currentGroup = [ tz ]
dateTimeArray = []
for (i between START_DATE && END_DATE) {
dateTimeArray.push(convertWithTZ(i, tz.label))
} foreach (tz2 in timezones) {
if (tz.continent != tz2.continent) {
next();
} dateTimeArray2 = []
for (i between START_DATE && END_DATE) {
dateTimeArray2.push(convertWithTZ(i, tz2.label))
} if (dateTimeArray.equals(dateTimeArray2)) {
currentGroup.push(tz2)
timezones.remove(tz2)
breakLoop();
}
}
GROUPS.push(currentGroup);
}
Running the script today (05.03.2020), we calculated 107 groups.
You can find the complete script on Github under the MIT License:
You can run the script on your own and play around with the list of time zones and the startdate and enddate of the algorithm to see different output throughout the years. For ecampe, if we would have run the script in 2005, we would have calculated 121 groups. I leave it up to you to figure out what changed in the meantime.
Remarks
The general algorithm is quite easy and in fact the first iteration was written within 2 hours. However, as always, the devil is in the details: Dealing with lots of copies of momentJS objects was something that we had to optimize to deal with a longer timerange. We also had to fine-tune the list of continents (using an allowlist) and the list of cities (using a denylist), as some of the labels cannot be used directly. One example is that Europe/Istanbul was listed, as well as Asia/Istanbul—which we simply mapped to Europe.
Last step(s)
In order to use the output in our system, we also had to generate a representative for each group. This could basically be any time zone of each list, but we wanted this to be the most-prominent one. Accordingly, we added a count field for each time zone — which was in our case the number of users that have already chosen this time zone. We have not shared this information on Github, but kept the sorting part of the algorithm. Feel free to use it with any number of your choice that you’d like it to be sorted by.
Last but not least, we wanted to automatically calculate a label for each group. Given the sorting above, this was fairly easy:
We sorted each list by the count field and extract the name of the city of the first 7 time zones. We also included a mapping from time zone -> city translation, in case you want to provide it with a special translation or internationalization.
Long story short
I presented an algorithm to group timezones into buckets based on three simple rules that define the similarity between time zones. The algorithm is based on a brute-force approach, representing each time zone as an array of days which are then compared against.
Discussion
I am very interested to hear your thoughts and experiences regarding this or other approaches.
- Do you have the same usecase? How did you solve it?
- Do you have another resource that I could look at?
- What would you have done different in my position?
If you are interested in connecting with me, please do so and please drop me a short line where you are coming from.
